Abstract
Structure-from-Motion -- the process of simultaneously estimating camera poses and 3D scene structure from a collection of images -- remains a central challenge in computer vision, with many open problems yet to be solved. Recent advances in feedforward 3D reconstruction have made significant strides in overcoming persistent failure cases of classical SfM methods, particularly in scenarios characterized by low texture, limited overlap, and symmetries. However, while feedforward approaches excel in these challenging conditions, they often face limitations regarding scalability, accuracy, or robustness, and typically fall short of classical methods in standard reconstruction settings. In this work, we systematically analyze these limitations and propose a new Structure-from-Motion pipeline by combining the respective strengths of classical and feedforward methods. Extensive experiments across multiple datasets show the benefits of our approach, achieving state-of-the-art results across a wide range of scenarios. We share our system as an open-source implementation at https://github.com/colmap/gluemap.
Video
Challenges Faced by SfM Algorithms
Classical structure-from-motion recovers cameras and 3D points from images by matching local features across views and optimizing geometry through multi-view constraints. It is scalable, accurate, and robust, but relies on multi-view feature tracks and fails in low-overlap, low-texture, or low-parallax scenarios.
Feedforward methods instead predict cameras and geometry end-to-end directly from images, without explicit feature matching or iterative optimization. They handle these hard cases well, but struggle with scalability, lag in accuracy on nominal scenes, and are less robust to symmetries, multiple components, and outliers.
|
accuracy |
scalability |
robustness |
low-overlap |
low-parallax |
low-texture |
| classical |
✓ |
✓ |
✓ |
✗ |
✗ |
✗ |
| feedforward |
✗ |
✗ |
✗ |
✓ |
✓ |
✓ |
|
classical |
feedforward |
| accuracy | ✓ | ✗ |
| scalability | ✓ | ✗ |
| robustness | ✓ | ✗ |
| low-overlap | ✗ | ✓ |
| low-parallax | ✗ | ✓ |
| low-texture | ✗ | ✓ |
The two regimes are complementary that each is strong where the other is weak.
We propose GLUEMAP, which glues them into a single pipeline that inherits the advantages of both.
Two Axes of Difficulty
To determine the design, we first identify two important structural properties determining performances of Structure-from-Motion systems.
Radius
Radius determines the minimum number of hops needed to exchange information across the graph.
Graph can have the same density with different radius.
Density
Density determines how many ways information can be exchanged.
Graphs can have different density with the same radius.
The performance of feedforward methods drops with increasing radius and stays relatively stable with different densities.
In contrast, our method inherits the performance of classical structure-from-motion system that it is more robust to increasing radius and benefits from higher density.
GLUEMAP Pipeline
The pipeline consists of four major stages: view graph initialization and feedforward local inference, global motion averaging and augmented bundle adjustment.
Local robustness is provided feedforward models while the scalability and acurracy is unlocked by the global optimization similar to classical structure-from-motion.
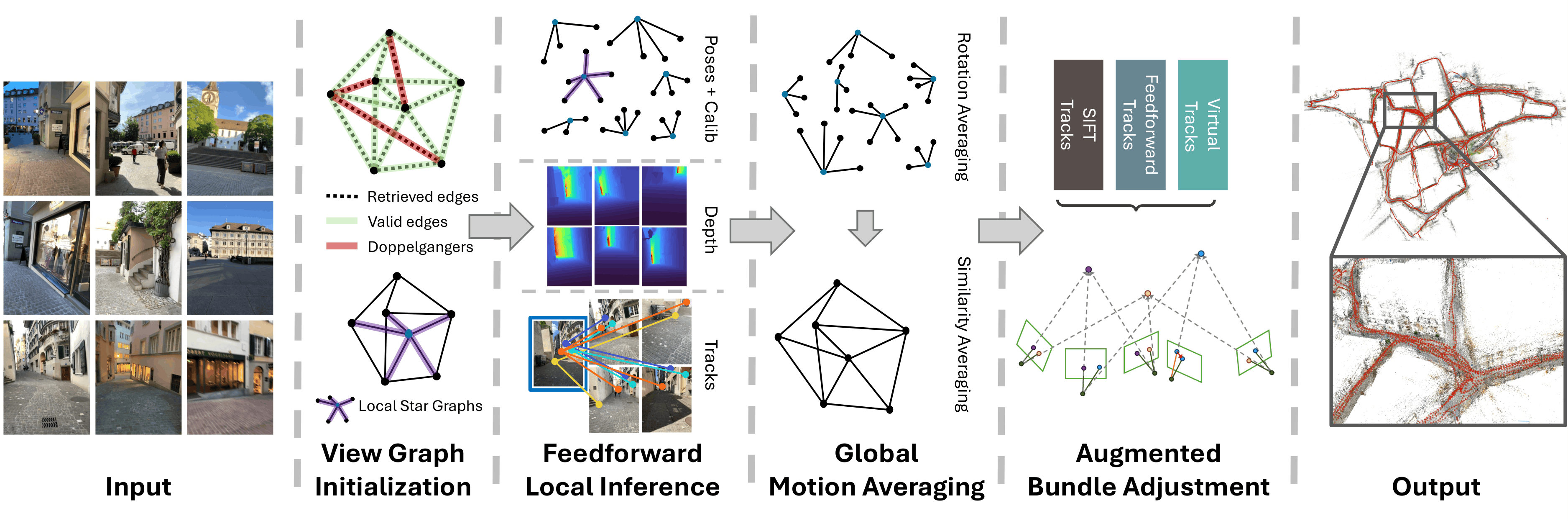
Augmented Bundle Adjustment
We combine three track sources: SIFT tracks for accuracy in textured regions, feedforward tracks for robustness under challenging conditions, and virtual tracks.
Virtual Tracks
Virtual tracks regularize relative pose where real tracks are absent or unreliable. We perturb the center view’s predicted depths with Gaussian noise and reproject the points into neighboring views as synthetic correspondences. Unlike real tracks, we keep observations that fall outside the frame or have negative depth, preserving constraints in directions classical tracks cannot cover.
We evaluate across five datasets spanning the six identified challenges.
We find that
- Feedforward models excel for local robustness.
- The classical method is more scalable and accurate.
- Combining them achieves the best performance.
Qualitative Results
| SIFT |
ALIKED + LightGlue |
GLUEMAP |
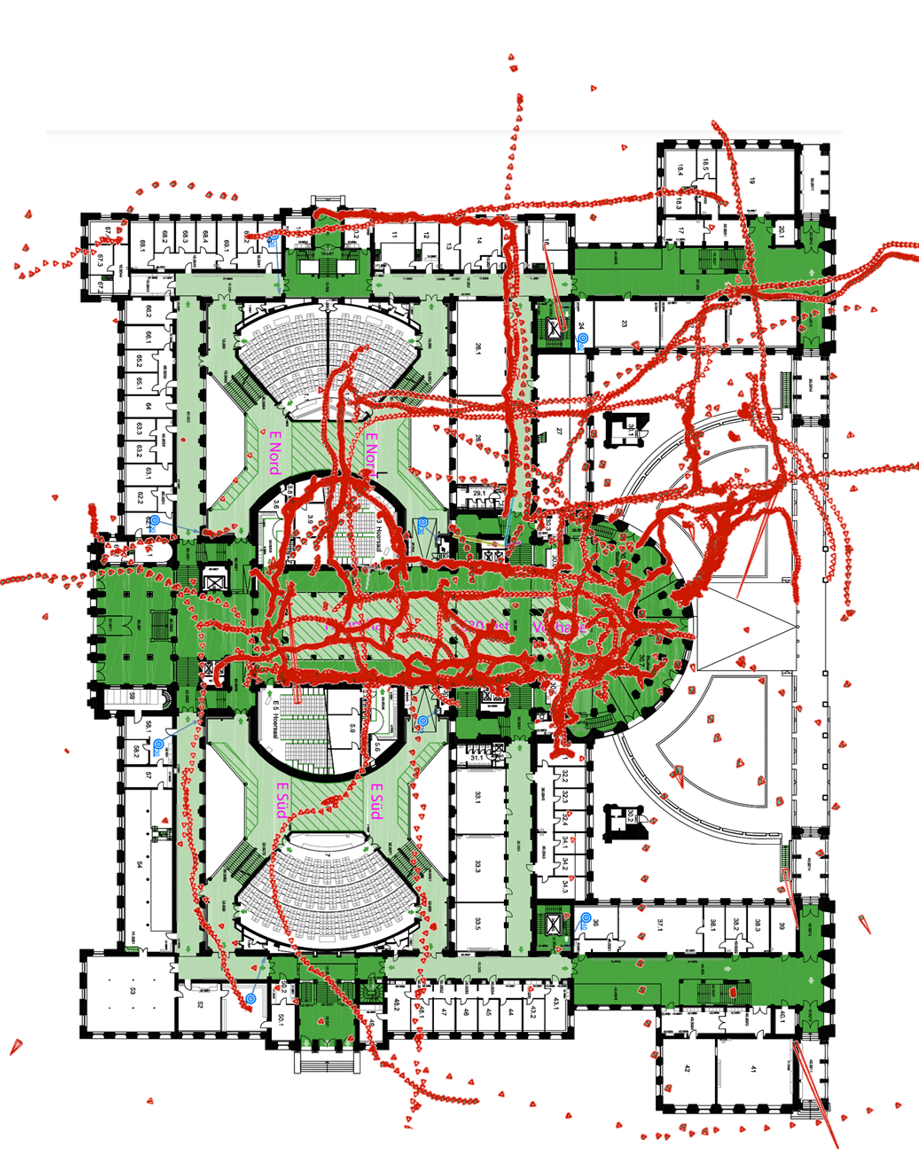 |
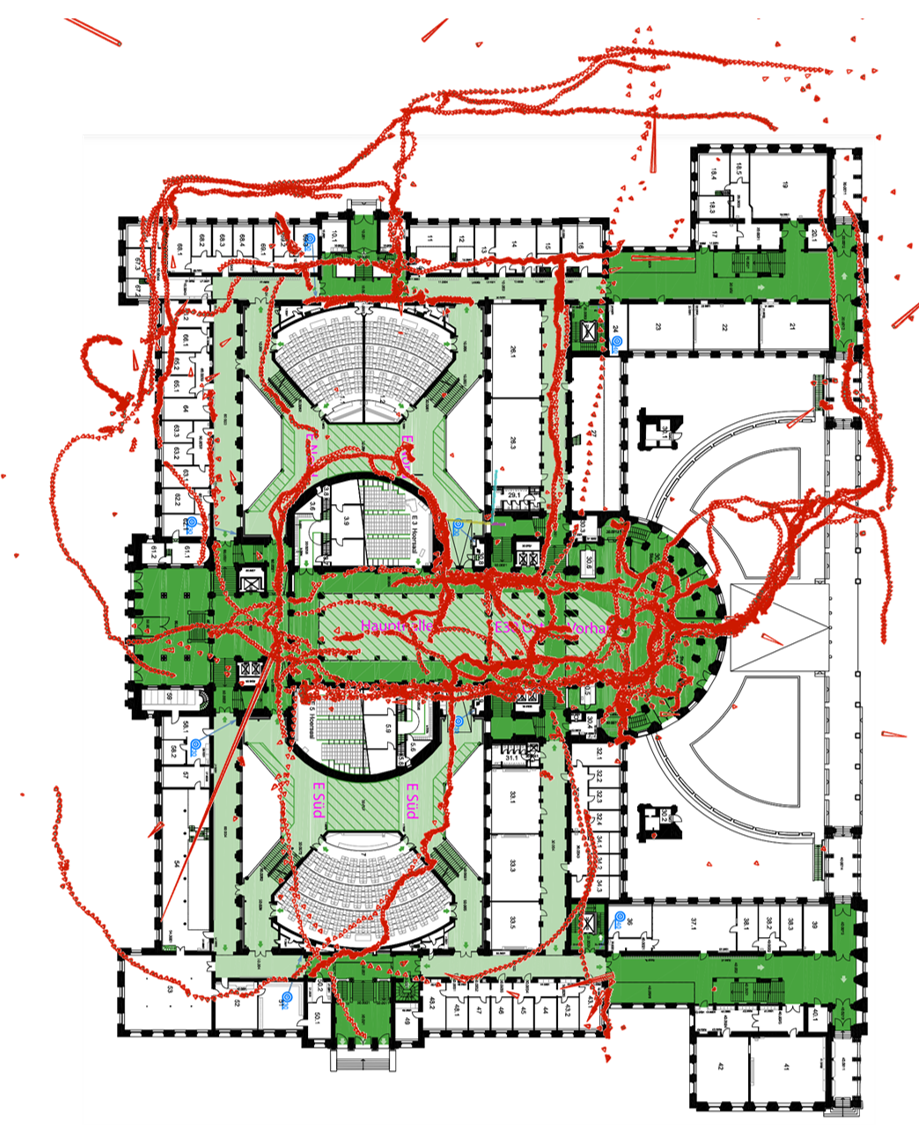 |
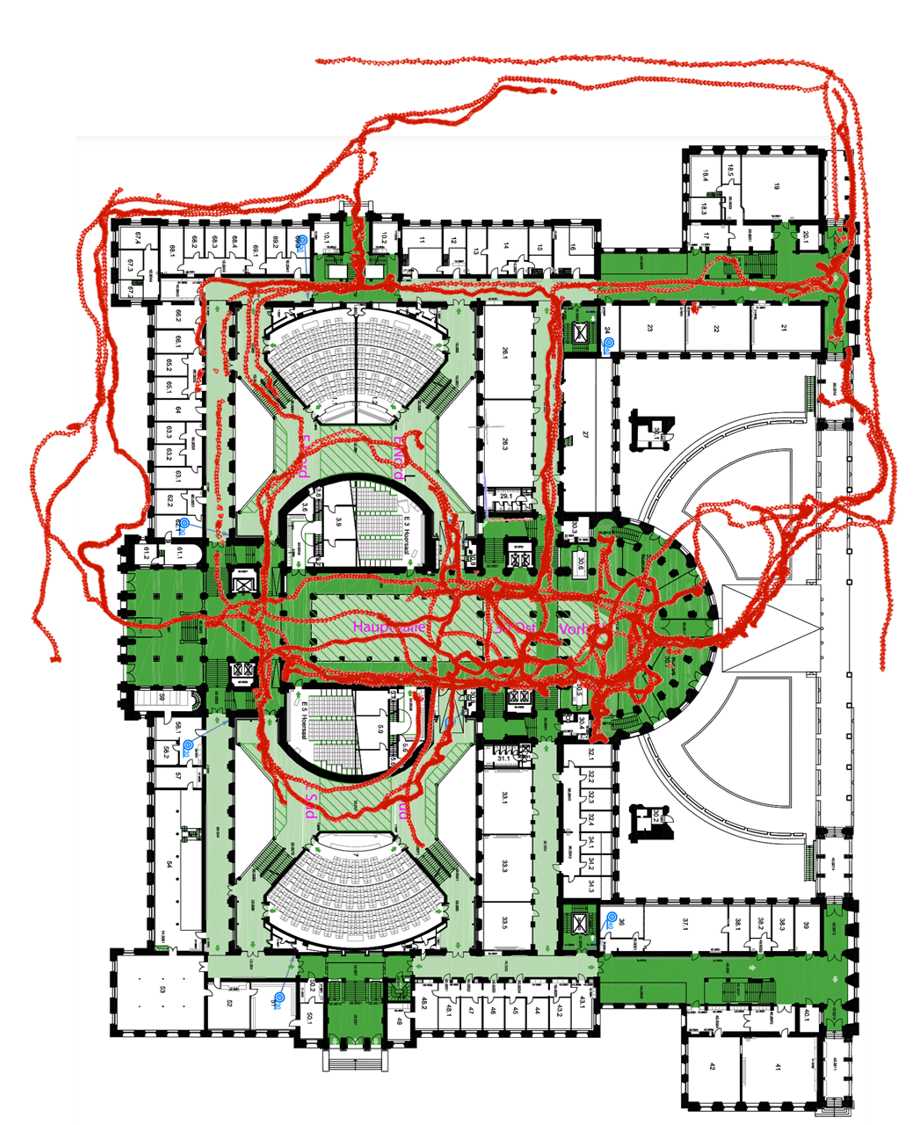 |
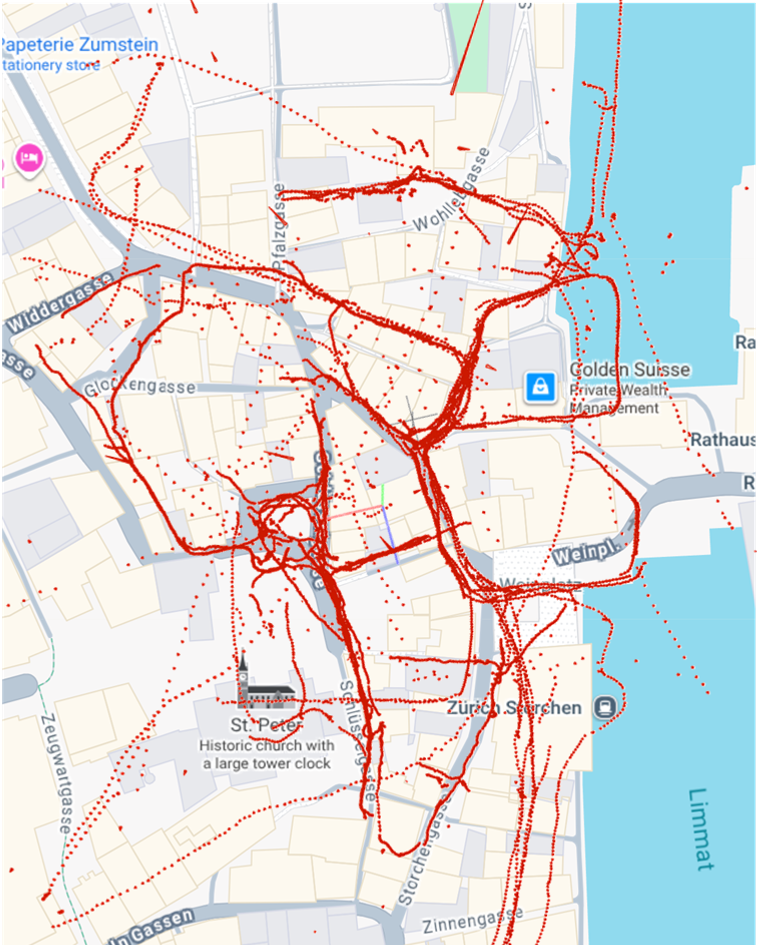 |
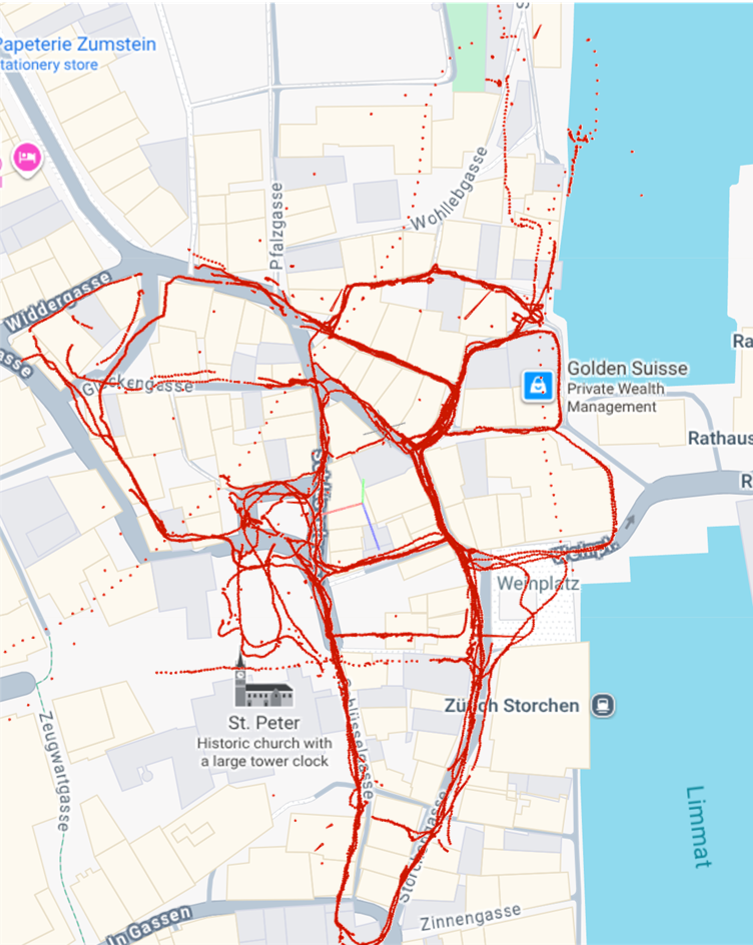 |
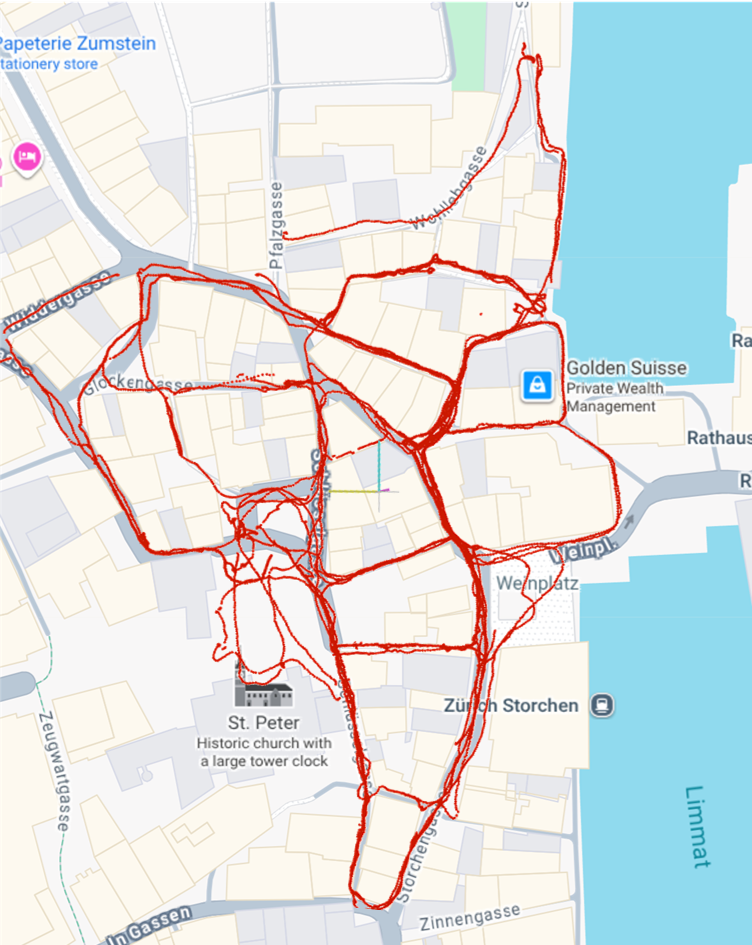 |
BibTeX
@inproceedings{pan2026gluemap,
author={Pan, Linfei and Sch\"{o}nberger, Johannes Lutz and Pollefeys, Marc},
title={Global Structure-from-Motion Meets Feedforward Reconstruction},
booktitle={Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026},
}