Abstract
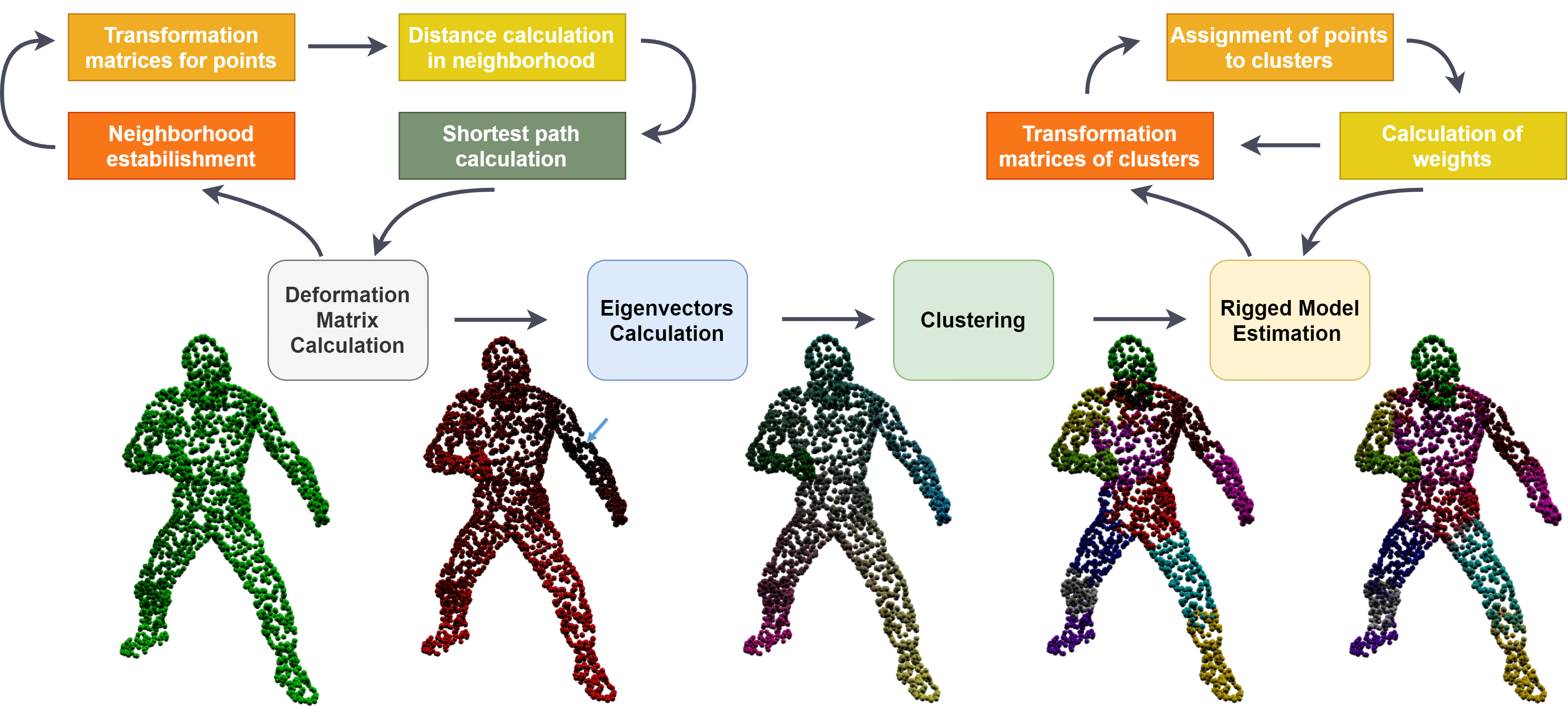
Recent progress in consumer hardware allowed for the collection of a large amount of animated point cloud data, which is on the one hand highly redundant and on the other hand incomplete. Our goal is to bridge this gap and find a low dimensional representation capable of approximation to a desired precision and completion of missing data. Model-less non-rigid 3D reconstruction algorithms, formulated as a linear factorization of observed point tracks into static shape component and dynamic pose, have been found insufficient to create suitable generative models, capable of generating new unobserved poses. This is due to the non-locality of the linear models, over-fitting to the non-causal correlations present in the data, which manifests in the reconstruction containing rigidly behaving not directly connected parts. In this paper, we propose a new method that can distinguish body parts and factorize the data into shape and pose purely using topological properties of the manifold-local deformations and neighborhoods. To obtain localized factorization, we formulate the deformation distance between two point tracks as the smallest deformation along the path between them. After embedding such distance in low dimensional space, a clustering of embedded data leads to close to rigid components, suitable as initialization for fitting a model-a skinned rigged mesh, used extensively in computer graphics. As both local deformations and neighborhoods of a point are local and can be estimated only from the part of the animation, the method can be used to recover unobserved data in each frame.
Video
Pipeline
Results